Getting the Most out of Augment Code
How we use Augment Code at Cyoda

This article was written by Google Gemini 2.5 Pro from a transcript of a workshop we held this week, and redacted by GPT-5 Pro and myself. See more about that at the end.
AI‑assisted development tools are reshaping how software gets built. Over the past six months we have integrated Augment Code into our day‑to‑day engineering work at Cyoda, and one lesson has become fundamental: using these tools well is a skill. It is not a single “magic prompt,” but a disciplined partnership that improves with practice. The gains are real, but they come from process, not luck.
This essay shares what has worked for us—our philosophy, the setup we rely on, and the habits that made Augment Code productive in real projects.
The Core Philosophy: AI Development as a Skill
Treat Augment Code the way you would treat a new instrument or sport. The first attempts feel awkward; feedback loops feel slow; and the tool makes confident mistakes. With repetition and structure the dynamics change: prompts become shorter and more precise; you learn what context matters; and you start to anticipate failure modes before they happen. The comparison we use internally is learning to ride a unicycle or fly a radio‑controlled helicopter. At first you wobble. With consistency you can do careful, precise work—and occasionally, genuinely impressive things.
Two implications follow from this mindset. First, results depend more on preparation than on improvisation. Second, the human remains firmly in the loop: judgement, verification, and guardrails are non‑negotiable.
Setting Up for Success: Preparation and Configuration
Good outcomes begin before any prompt is written. Augment Code gives you places to encode intent and context; using them up front saves time later.
User Guidelines. We keep a concise, durable set of rules in the global guidelines for Augment Chat—tone, coding conventions, review expectations, and “do‑nots.” These are broad policies we want applied across projects.
Agent Memories. For project‑specific needs we maintain short, factual notes in the agent’s memory via the chat interface: domain terms, module boundaries, repository layout, and known constraints. The agent may also add to these over time; we audit and prune to keep them accurate.
Modes of Operation. Augment Code has two modes: Chat and Agent. Chat mode is advisory: it proposes approaches and snippets without touching the code or using any of the tools. Agent mode can modify files and run commands. When we enable Agent mode’s “auto” capabilities, we do so with guardrails and close supervision. The more power you grant, the more important your safety habits become.
Workflow and Best Practices: The Human in the Loop
Safety first
We explicitly instruct the AI never to commit or push code. Also, we’ve see confusion about filesystem paths, which could in theory spiral into destructive actions in the wrong directory, and network operations expand the blast radius. We include instructions to assert that it has the right working directory at the start of a task, but one must keep an eye on this. We avoid placing public secrets in any files the AI can access.
In our experience, guidelines are strong hints, not hard guarantees, so we assume occasional drift and defend accordingly.
Iteration as the default
We work in small, isolated chunks. Instead of one sprawling conversation, we prefer many focused threads, each with a single, clear objective. Before starting, we create a reversible checkpoint—an empty commit, a throwaway branch, or a local history tag—so that rolling back is cheap if the AI takes a wrong turn. While the agent works, we supervise like we would a junior developer: we read diffs, ask the AI to explain its plan, and interrupt if assumptions look off. We test the output before we commit anything. For a new task we often start a fresh thread, which prevents old context from colouring new work.
Advanced Techniques and Observations
Give the right context, not all the context
More context usually helps, but indiscriminate context can confuse. We highlight relevant code blocks before prompting, and we use @‑references to point to specific files, functions, or configuration items. This narrows the search space and reduces speculative changes. We use any “refine prompt” features carefully; they can be helpful for structure, but they can also introduce inventiveness we didn’t ask for. We prefer to write the smallest clear instruction and iterate.
Let the AI help with testing—then verify
Augment Code can be effective at end‑to‑end checks: start the service, hit endpoints, inspect logs, and report what happened. We ask it to gather proof (responses, log lines, timestamps) and to produce minimal reproduction steps when it finds a defect. For front‑end work we improved reliability by configuring the Playwright MCP so the agent can drive a real browser. This closed a gap where the AI “tested” code only in theory. Even so, we read the results critically and re‑run key steps ourselves. “It passed locally” is not the same as “it’s ready.”
Design first with diagrams
When the change is non‑trivial—new modules, cross‑cutting concerns, non‑obvious data flows—we design before we build. Lightweight diagrams (Mermaid has been sufficient) clarify names, relationships, and control flow. We create them with another assistant and feed them to Augment Code as the source of truth for the implementation thread. Keeping design and implementation in separate chats keeps the builder from becoming “too opinionated.” The sequence becomes: agree the design; implement to the design; test to the requirements, all in separate threads.
Search before you build: prefer reuse
The agent often defaults to writing code from scratch. Make “reuse first” part of the design: require a check for available third‑party libraries and for components already present in the codebase before proposing new code. This prevents re‑implementing solved problems and helps even with small features, especially in larger codebases.
Infrastructure and model differences
We’ve seen noticeable differences across environments and models. When Augment Code uses the Terminal tool, the results on Linux have been smoother than on Windows. GPT-5 tends to be better at the design/documentation tasks than Claude Sonnet 4. GPT-5 also seems to be better than Claude at the moment for Python coding, but responds slowly; Claude is faster at small refactors but less reliable on long‑form reasoning. We use almost exclusively Claude for Java/Kotlin. We pick the model to fit the task rather than expecting one profile to excel at everything, and we re‑evaluate choices as the tools evolve.
The Double‑Edged Sword: Managing AI‑Generated Output
Tests are code—treat them that way
Generated tests can be verbose or redundant. Sometimes the AI mocks so aggressively that the test ceases to verify anything meaningful. We ask for the minimum test that proves behaviour, and we request targeted coverage where gaps matter. We review tests with the same care we review production code and prune anything that adds noise without protecting a real contract.
Documentation multiplies quickly
The AI is excellent at producing comments and reference docs. The cost shows up later: keeping those artifacts aligned with the code. Drift is more than cosmetic. Humans—and the AI—will take stale docs as truth and “fix” correct code to match them. We manage this by keeping documentation close to the source, by tying updates to pull requests, and by being willing to delete docs that no longer earn their keep. When in doubt, a smaller set of truthful docs beats a larger set of plausible ones.
Beware of the fact that the ability to rapidly create documentation in a sense creates a lock-in effect on using AI to code. If you subsequently refactor code yourself, it can become a real pain to ensure all docs are aligned. You’ll find yourself looping in the AI. How to treat documentation effectively is still a work in progress for us.
Final Thoughts
AI‑assisted development is a force multiplier when paired with preparation, guardrails, and a steady feedback loop. With Augment Code we treat the AI as a partner: we set expectations in guidelines and memories; we scope work tightly; we checkpoint before changes; we supervise actively; and we test before we trust. The result is not an autopilot, but a faster, calmer way to build—one where the engineering team retains judgement while the tool shoulders more of the busywork. Used this way, Augment Code has become part of how we write software, not just another app on the toolbar.
How was this produced?
We held a meeting this week on how our team uses Augment Code to gather and collect insights and best practices for all. The Google meet was transcribed via Google Gemini, which also produced the minutes. These minutes were fed into Google Gemini 2.5 Pro using the following prompt:
I want you to create a draft substack article "How we use Augment Code at Cyoda" based on the minutes of this meeting with the aim to provide the developer community with useful insights into using Augment Code.
For clarity and presentation, with the aim of producing an article that is engaging and informative, without any hyperbole or marketing speak.
Include ALL insights and comments made in the minutes. They are all relevant.
Structure the document in a coherent fashion; it doesn't necessarily have to follow the same sequence as the minutes themselves. Use a proper passive voice when presenting facts/features of Augment Code.
Produce a downloadable markdown document of the result.
The writeup contained references to people, so I followed up with
Remove any references to people, or that this emerged from a brainstorming session.
I didn’t like the style that much, although it managed to include all aspects we discussed. So I took that writeup and gave it to GPT-5 Pro
I want you to improve this draft substack article for clarity and presentation, with the aim of producing an article that is engaging and informative, without any hyperbole or marketing speak. The idea is to provide useful insights for the developer community.
Produce a downloadable markdown document of the result.
The result is the above. I didn’t have to redact more than a few lines and added a paragraph by hand on the AI lock-in effect with documentation. The rest is pure AI flow.
Although the content is entirely AI generated, it fully mirrors the results of the workshop. I stand by the content of this writeup.
Java/Kotlin Project Rule-Set
We primarily use JetBrains IntelliJ IDEA for development. Unlike the Augment Code plugin in Visual Studio, IntelliJ does not support built-in rule-sets. To work around this, each project includes a .augment/rules folder containing a README.md and individual rule files. We then inject an instruction into the Agent Memories, telling it to always review the .augment/rules/README.md file before starting any task.
Always check and follow the rules in @/.augment/rules by reading the @/.augment/rules/README.md file before starting any new task.
This is what our README looks like:
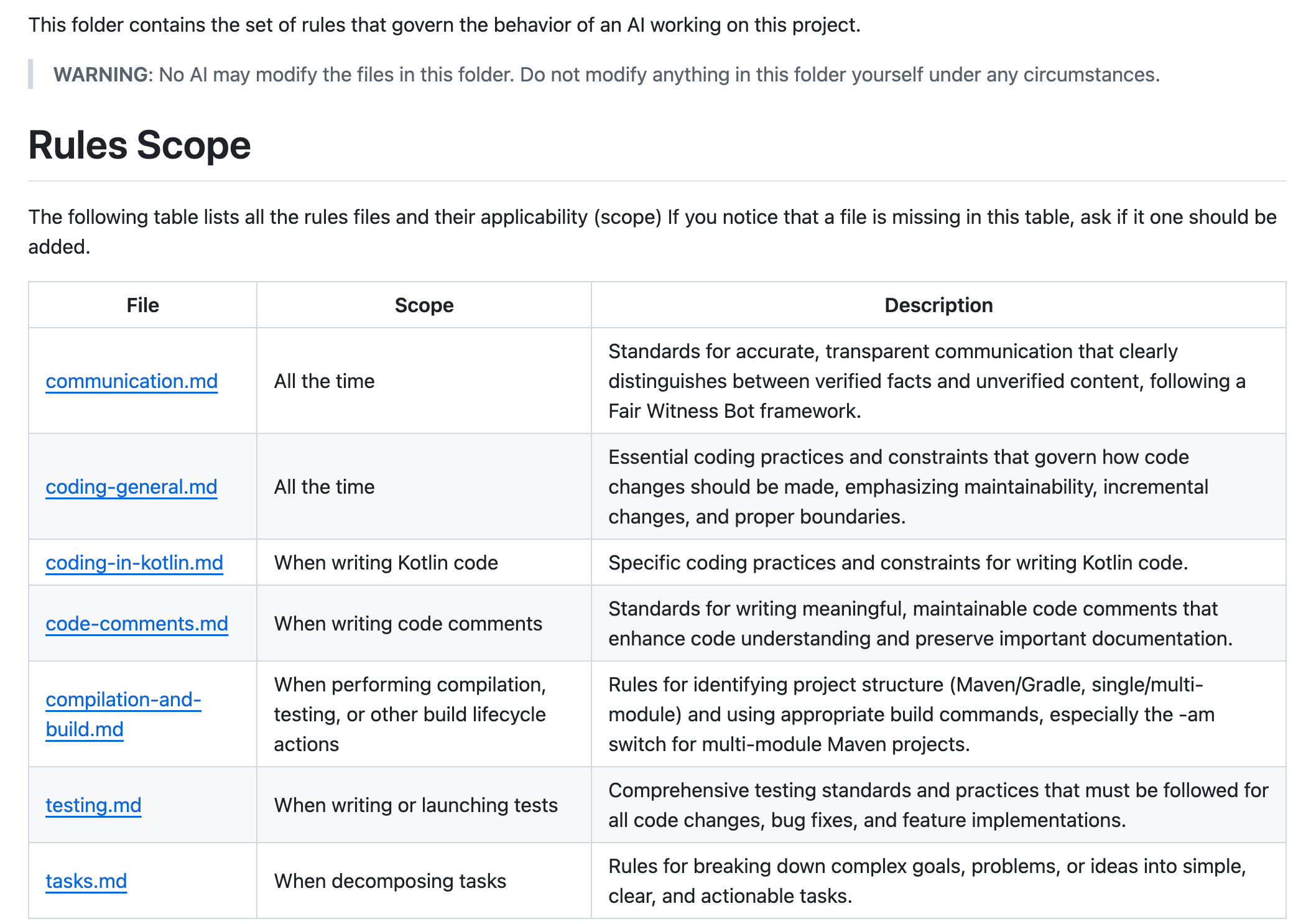
You can find a full example rule-set here: https://github.com/Cyoda-platform/java-client-template/tree/main/.augment/rules